



28. November 2019 von Steffen Albrecht
Der Einfluss von “Clean Code” auf die menschliche Wahrnehmungsverarbeitung
Clean Code - jeder hat schon davon gehört, jeder findet es irgendwie toll und keiner will dafür bezahlen. Bei Projektstart sind Entwicklerinnen und Entwickler, die Tests schreiben und ihren Code und ihr Design sauber halten, langsamer als ihre anderen Kolleginnen und Kollegen. Und das ist nicht nur aus Sicht der Projektleitung eine durchaus realistische Einschätzung.
Schauen wir aus rein wirtschaftlicher Sicht auf den Output einer Entwicklerin oder eines Entwicklers beziehungsweise des gesamten Entwicklungsteams: Hier zählt nur die Anzahl der gelieferten Teile des zu bauenden Produktes pro Zeiteinheit (unter der Annahme, dass auch das “Richtige” gebaut wird). Es gilt, diese „Geschwindigkeit“ nicht nur über den gesamten Projektverlauf zu halten, sondern idealerweise auch zu steigern. Um dies zu erreichen, ist es naheliegend sich damit auseinanderzusetzen, womit Entwicklerinnen und Entwickler den größten Teil ihrer Arbeitszeit verbringen - und das ist das Lesen von Quellcode!
Das Rätseln über das, was im Quellcode steht, kostet Zeit (und Geld) und sollte daher minimiert werden. Mögliche Lösungen bieten zahlreiche Clean-Code-Praktiken, wie sie zum Beispiel von Robert C. Martin in seinem gleichnamigen Buch bereits seit mehreren Jahren empfohlen werden. Dennoch werden diese Praktiken so oft missachtet, im schlimmsten Fall so krampfhaft angewendet, dass sie eher das Gegenteil bewirken. Das Verständnis, wie unsere Wahrnehmungsverarbeitung funktioniert, ist daher von entscheidender Bedeutung, um den Sinn von Clean Code nicht nur zu verstehen, sondern auch die Prinzipien auf den jeweiligen Projektkontext anwenden zu können. So kann eine Code-Basis geschaffen werden, die zu jedem beliebigen Zeitpunkt gut lesbar und leicht verständlich bleibt.
Wie uns bekannte Muster beeinflussen
Zu Beginn eine kleine Übung: Die folgende Abbildung enthält drei Hinweise, um die einfache und simple Frage zu beantworten: Welche Linie ist die längste?
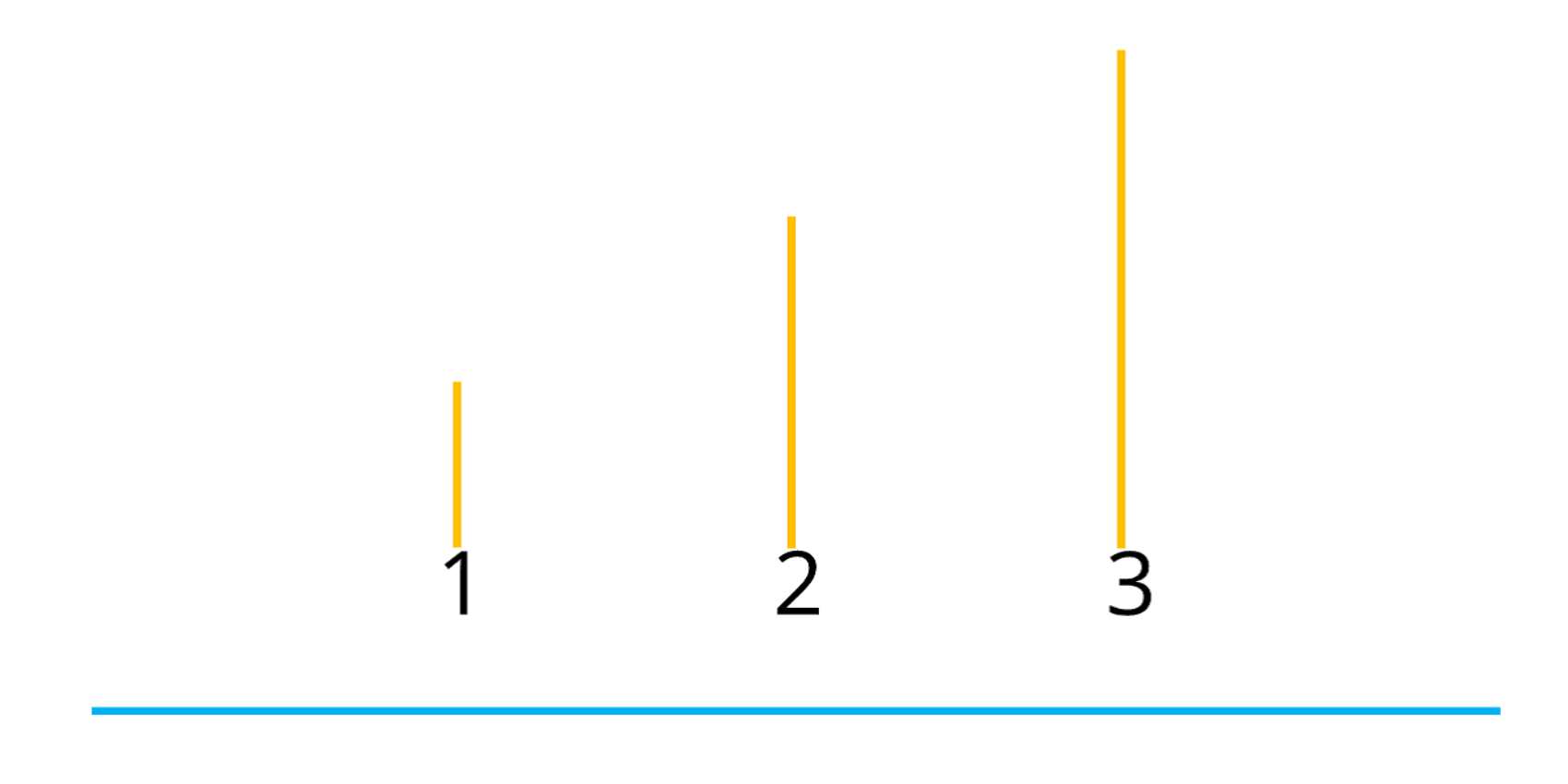
Eine illustrierte Abbildung in einer gewohnten Darstellungsform
So, Hand aufs Herz, wer von euch hätte jetzt sofort mit „Linie 3“ geantwortet oder zumindest den ersten Impuls dazu gehabt? Ich muss euch aber enttäuschen, denn „Linie 3“ ist leider die falsche Antwort. Aber keine Sorge, ihr seid nicht die Einzigen, die hier falsch antworten.
Von den drei Hinweisen - 1. die Beschriftungen, 2. die Farben, 3. die Linien selbst - sind die ersten beiden vollkommen irrelevant und verschleiern den Blick auf alle Linien. Sehen wir uns die Abbildung noch einmal ohne ablenkende Störinformationen an:

Die oben gezeigte Abbildung in einer alternativen Darstellungsform
Nun ist leicht zu erkennen, dass die untere Line eindeutig die Längste ist. Warum ist das bei der ersten Abbildung nicht sofort aufgefallen? Schuld sind die Beschriftungen sowie die farblichen Hervorhebungen. Die Darstellung einer solchen Abbildung mit unterschiedlichen Farben und Beschriftungen ist euch mit Sicherheit bestens vertraut, aber an dieser Stelle unwichtig. Es ging schließlich um die längste Linie – unabhängig von der Farbe oder Bezeichnung.
Der Grund für diese Fehlannahme ist recht einfach: Man denkt nicht mehr wirklich darüber nach, da die Aufgabe mit Leichtigkeit gelöst werden kann – zumindest glaubt man, dass es so ist.
Wahrnehmung als Ergebnis zweier Systeme
Laut diesem Wahrnehmungsmodel von Daniel Kahneman, Psychologe und Nobelpreisträger für Wirtschaft, erfolgt die Verarbeitung unserer Wahrnehmung beziehungsweise Sinneseindrücke durch zwei verschiedene Systeme. Kahneman bezeichnet diese lediglich als „System 1“ und „System 2“.
System 1 ist praktisch in jedem Lebewesen, das über ein zentrales Nervenzentrum verfügt, vorhanden – sozusagen „alt“ und perfekt ausgereift. Dieses System ist schnell, benötigt keinerlei körperliche oder gar geistige Anstrengung und basiert im Wesentlichen auf Mustererkennung. Wird ein passendes Muster gefunden, löst System 1 also die damit verknüpfte Reaktion aus.
Relativ neu und nur bei wenigen Arten vorhanden ist dagegen System 2. Dieses ist nun für die Analyse komplexer Daten sowie für die Verknüpfung von bestehendem Wissen zu neuen Lösungen verantwortlich. Im Gegensatz zu System 1 ist dieses System sehr langsam, faul und setzt sich nur in Gang, wenn es benutzt wird. Ihr merkt es meistens dann, wenn ihr den ganzen Tag Anforderungsspezifikationen lest oder den Spaghetti-Code eurer Vorgänger entschlüsselt und der Kaffee nicht mehr wirkt. System 2 stellt seine Arbeit also in der Regel sofort dann ein, wenn System 1 ein passendes Muster gefunden hat.
Nichts anderes wollte ich mit der Frage „Welche Linie ist die Längste?“ beweisen. Da auch eurer System 2 faul ist, versucht es, alle Daten aus der Analyse herauszunehmen, die von eurem System 1 bereits erkannt wurden. Mit anderen Worten: Über ein vermeintliches Muster, das allen Beteiligten vertraut ist, wird nicht weiter nachgedacht, da die Lösung augenscheinlich bereits gefunden wurde.
Meine Beschreibung von Kahnemans Wahrnehmungsmodel mag grob vereinfacht sein und ist doch die Quintessenz des Ziels, das durch die Anwendung von Clean-Code-Praktiken erreicht werden soll: Einerseits soll möglichst viel des Quellcodes durch System 1 erfasst werden, andererseits soll es System 2 so leicht wie möglich gemacht werden, auch den Rest zu entschlüsseln. Zudem muss vermieden werden, dass System 1 durch irreführende Informationen zu falschen Schlüssen gelangt – wie es beispielsweise bei der ersten Abbildung der Fall war.
System 1 und 2 in der Praxis
Wie lässt sich das eher theoretische Konstrukt von Daniel Kahneman auf die Softwareprojekte und damit in die Praxis übertragen? Ich denke, am deutlichsten wird es bei den Themen „Einheitlichkeit“, „Namen“ und „Kommentare“:
Einheitlichkeit
Beginnen wir mit dem Punkt „Einheitlichkeit“. Die Fähigkeit von System 1 besteht darin, Muster nicht nur effizient zu erkennen, sondern auch zu erlernen. Diese kann dazu genutzt werden, um Quellcode schnell zu erfassen und verstehen zu können. Am Bekanntesten ist hierbei die Verwendung von Entwurfsmustern beziehungsweise Design Patterns. Das Erlernen und die korrekte Anwendung dieser Muster spart nicht nur Zeit bei der Implementierung, sondern auch beim Lesen. Ihr müsst nicht mehr aktiv darüber nachdenken, was ein bestimmter Code im Detail macht, denn euer gut trainiertes System 1 teilt es euch sofort mit.
Einheitliche Codierungsrichtlinien können System 2 ebenfalls dabei helfen, den Code leichter zu verstehen, wenn System 1 diesen bereits als „vertraut“ erkannt hat. Für die Arbeit im Entwicklungsteam bedeutet es, dass hierbei die Richtlinien regelmäßig dahingehend geprüft werden müssen, ob sie noch von allen Teammitgliedern verstanden und akzeptiert werden.
Namen
Auch Namen können für System 1 eine Art Muster sein. Gegenstände, Lebewesen, Personen, Konzepte und alles, was wir benennen wollen, hat einen Namen. Je vertrauter uns diese Bezeichnungen sind, desto leichter fällt es System 1 einen passenden Aktions-Match zu finden: Ein Bild, eine Erinnerungen oder manchmal nur ein Gefühl – egal ob vollkommen unbewusst und praktisch nicht abschaltbar. Unbekannte oder sogar widersprüchliche Namen aktivieren System 2. Befindet ihr euch gerade in einem Flow-Zustand, ist dieser damit beendet. Nun seid ihr dazu gezwungen, aktiv darüber nachzudenken, um das Unbekannte beziehungsweise Widersprüchliche aufzulösen. Erst dann könnt ihr in den Flow zurückkehren.
Es zahlt sich schnell aus, wenn ihr euch Zeit für gute Klassen-, Methoden- oder Variablennamen nehmt und gegebenenfalls auch vor Umbenennungen nicht zurückschreckt.
Kommentare
Dass Kommentare in der Programmierung lügen, ist bekannt. Was ist an ihnen problematisch und könnt ihr sie nicht doch einfach ignorieren? Das ist leider nicht so einfach möglich, wie ihr bei der Frage nach der längsten Linie in Abbildung 1 gesehen habt. Und selbst wenn Kommentare nicht lügen, verführen sie doch zu geistiger Faulheit. Warum sollte sich System 2 noch mit dem Code beschäftigen, wenn doch alles im Kommentar steht? Kommentare solltet ihr daher als das sehen, was sie wirklich sind, nämlich als Hinweise auf Code-Stellen, die dringend einer Überarbeitung bedürfen. Ein guter Code benötigt dann auch keine weitere Erklärung.
Fazit
Wenn es gelingen soll, einerseits einen guten Code zu schreiben und andererseits die Clean-Code-Praktiken sinnvoll anwenden zu können, ist ein gewisses Grundverständnis über die menschliche Wahrnehmungsverarbeitung unumgänglich. Wie ihr an dem Beispiel gesehen habt, verlässt sich der Verstand gerne auf gewohnte Muster und ist zu faul, um mögliche Alternativen zu erkennen, wenn ein Problem gelöst zu sein scheint.
Ihr möchtet euch näher mit diesem Ansatz beschäftigen? Dann empfehle ich euch Daniel Kahnemans Bestseller „Schnelles Denken, langsames Denken“ als guten Einstieg.
Wenn ihr euch für Clean Code in der Softwarearchitektur interessiert, werft auch einen Blick in den Blog-Beitrag von Wolfgang Wünsche. Weitere spannende Beiträge aus der adesso-Welt findet ihr übrigens in unseren bisher erschienenen Blog-Artikeln.

Kategorie: |
|
Schlagwörter: |
Clean Code Softwareprojekte |