



21. Jänner 2021 von Libor Karger
Optimierung von Bankprozessen – ein großes Potenzial für Künstliche Intelligenz
Die Clearstream Banking SA, eine 100-prozentige Tochter der Deutsche Börse AG, hat in einer Auseinandersetzung mit der US-Exportkontrollbehörde Office of Foreign Assets Control (OFAC) einen Vergleich erzielt, der eine Zahlung von 152 Mio. Dollar vorsieht. Bei der Auseinandersetzung ging es um einen Verstoß gegen Sanktionen, welche gegen den Iran verhängt worden waren.
Der Streit mit den US-Behörden kommt die Commerzbank teuer zu stehen. Deutschlands zweitgrößtes Geldhaus muss 1,45 Milliarden Dollar zahlen, um Vorwürfe wegen Sanktionsverstößen und Geldwäsche loszuwerden.
Das sind zwei Beispiele, die zeigen wie wichtig der Surveillance-Bereich, also die Überwachung von Prozessen aus regulatorischen und Compliance-Gründen, für Banken ist. Bei der Abwicklung von Transaktionen erfolgen deshalb unterschiedliche Echtzeitprüfungen – sogenannte Controls. Dabei werden alle Transaktionen auf Betrug, Sanktionen oder Geldwäsche überprüft. Das Ziel einer Bank ist es, möglichst hohe Erkennungsquoten von Verstößen zu erreichen.
Für solche Überprüfungen setzen Banken auch heute schon automatische Systeme ein. Allerdings erreichen diese Systeme keine hundertprozentige Erkennungsrate. Solche Systeme erkennen einen gewissen Prozentsatz automatisch und steuern die restlichen Transaktionen auf eine manuelle Bearbeitung aus. Wenn man davon ausgeht, dass große Banken in der Größenordnung von hunderten Millionen Transaktionen am Tag abwickeln und davon im Idealfall 90 bis 95 Prozent durch bisherige Systeme automatisch bearbeitet werden können, kann man den gewaltigen manuellen Aufwand erkennen.
Projektbeispiel: System zur Transaktionsüberprüfung auf Sanktionen
Hier gibt es einen sehr großen Angriffspunkt für den Einsatz von Methoden der Künstlichen Intelligenz. adesso hat für eine große internationale Bank ein System gebaut, das in der Lage ist, die manuell zu bearbeitenden Transaktionen bei der Überprüfung auf Sanktionen um bis zu 70 Prozent zu reduzieren. Im Folgenden werde ich dieses System, die Architektur und den Einsatz von Methoden der Künstlichen Intelligenz näher beleuchten.
Systembeschreibung: Über die Anforderungen des Teilsystems
Von Anfang an standen hohe Anforderung an Flexibilität und Variabilität im Vordergrund des Teilsystems, das für die Prüfung von Sanktionen zuständig war. Schließlich müssen an dieser Stelle viele unterschiedliche Überweisungsformate abgedeckt werden. Die Anwendung sollte an spezielle Gegebenheiten schnell anpassbar sein. Gerade bei den Überweisungsformaten ist die Spannweite groß, da hier formale Formate – beispielsweise SEPA – aber auch viele andere semiformale Formate zu berücksichtigen sind. Die Entitätserkennung für zum Beispiel Anschrift und Name im Freitext ist maschinell durch das Programmieren sehr schwierig herzustellen, da diese zu komplex sind. An dieser Stelle hilft das Natural Language Processing, dass in der Lage ist, aus dem Textzusammenhang Satzbestandteile als Entitäten zu extrahieren. Hierzu muss ein spezifisches Modell trainiert werden, das auf die Gegebenheiten in den Überweisungstexten optimiert wird und diese Entitäten erkennen kann.
Darauf aufbauend, bedarf es eines Regelwerks, das die erkannten Entitäten in unterschiedlichen Sanktionslisten finden kann und wenige False-Positives produziert. False-Positives sind in diesem Zusammenhang Übereinstimmungen – zum Beispiel bei Firmennamen ohne den Kontext der Anschrift.
Gleichzeitig musste die Erkennung nachvollziehbar und reproduzierbar sein, damit das System vom Auditor überprüft werden kann.
Architektur: Über den Aufbau des Systems
Das System teilt sich in mehrere Hauptkomponenten auf, die intern nach der Zwiebelarchitektur zerfallen und über Adapter mit der Außenwelt kommunizieren.
Als Kerntechnologie wurde wegen der Leichtgewichtigkeit und Flexibilität das Spring Boot Framework mit Java ausgewählt. Die Programmiersprache Python ist der de-facto Standard im Bereich von ML und zusammen mit dem Framework spaCy für das Natural Language Processing und die Entitätserkennung zuständig. spaCy basiert auf Neuronalen Netzen.
Es entstanden drei Hauptkomponenten Import/Export, Suche und AI/ML. Diese sind jeweils als ein Microservice konzipiert. Die Gründe dafür lagen in dem Technologiemix und in der Anforderung an den hohen Durchsatz, der durch redundante Auslegung der Komponenten erzielt wird.
Das Diagramm bietet einen groben Überblick über die Anordnung und Kommunikation der Komponenten mit dem Systemkontext und der Beziehung untereinander.

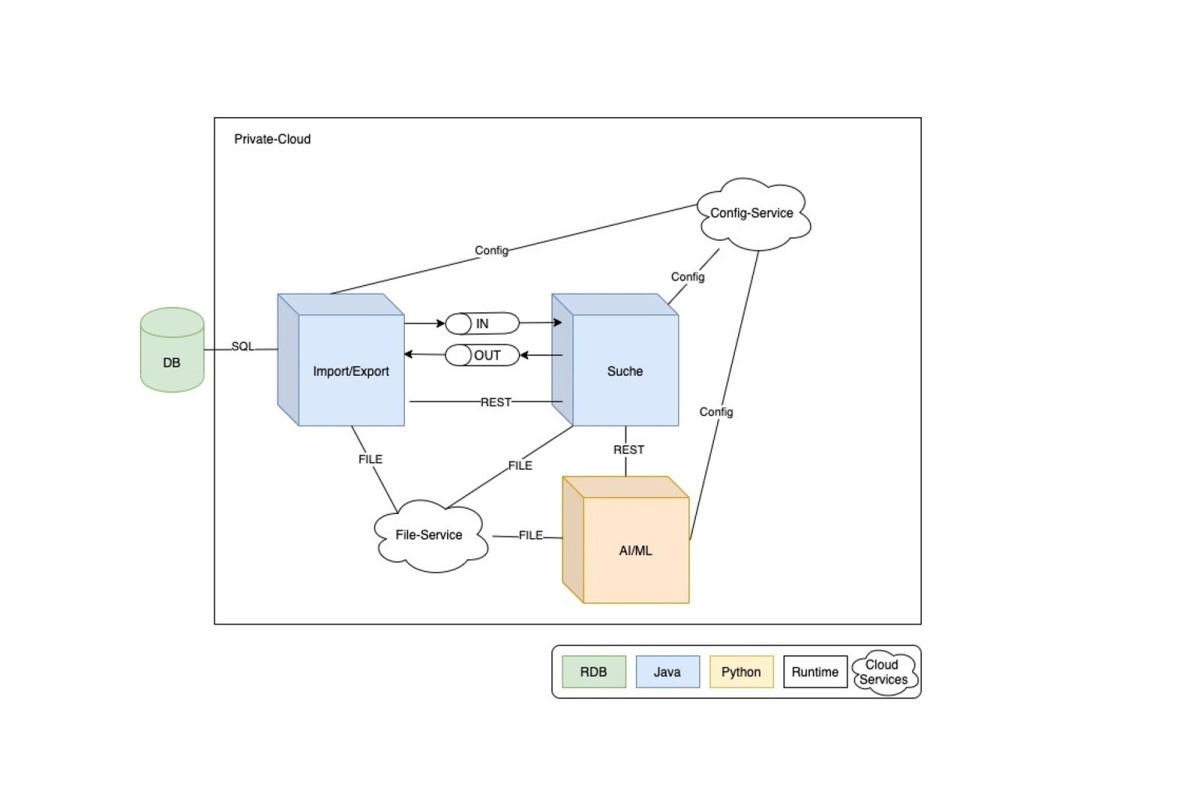
Die Kommunikation zwischen den Komponenten erfolgt synchron über REST und asynchron über Messaging Queues. Der Austausch innerhalb der Komponenten wird technologieneutral über das JSON Format gelöst.

Komponenten und ihre Aufgaben
Methoden der ML
spaCy ist eine OpenSource Bibliothek für das Advanced Natural Language Processing in Python und für den produktiven Einsatz geeignet. In dieser Lösung übernimmt spaCy die Aufgaben der Extraktion von Entitäten. Dazu wird das Name Entity Recognition Feature von spaCy benutzt. Die Extraktion von Named Entities benötigt ein spezifisches Modell für ein neuronales Netz, das trainiert werden muss. Dieses Modell wird oft optimiert, um noch bessere Ergebnisse zu erzielen. spaCy bietet dazu einige Hyperparameter an, die das Lernen des neuronalen Netzes beeinflussen. Die Modelle liegen statisch vor und können geladen werden. spaCy bietet eine Vielzahl von bereits trainierten Modellen zum Herunterladen an - diese eignen sich jedoch nicht für diese Aufgabe.
Daher lag ein besonderes Augenmerk auf den Quelldaten, die zum Trainieren des Modells benutzt werden. Synthetische Daten eigneten sich hier kaum, da hier die Gefahr besteht, dass das Modell nur so gut ist, wie der Algorithmus für die Erstellung der Daten. Anonymisierte oder pseudonymisierte Daten aus der Produktion eignen sich für die Erstellung der Modelle tendenziell besser. Produktionsdaten sind immer die erste Wahl, solange der Datenschutz dies erlaubt.
Damit das neuronale Netz eigene Entitäten selbst lernen kann, müssen die Daten annotiert werden. Dies kann zum Beispiel mit Doccano erstellt werden. Die Textdaten und die Metadaten aus dem Annotieren werden beim Training des neuronalen Netzes benutzt.
Das bessere Modell wird nicht durch eine Masse ähnlicher Daten, sondern mit großer Varianz der Texte in den Daten erzielt. Aus der Gesamtdatenmenge werden ein Viertel der Daten zurückgehalten, um das Modell zu prüfen und drei Viertel der Daten, um das Modell zu trainieren.
Das Training wird anhand des Error-Gradients der Loss-Function bewertet, das den Zusammenhang zwischen erkannten Daten und erwarteten Ergebnissen während des Trainings des neuronalen Netzes ermittelt. Darauf aufbauend werden weitere Optimierungen ausgemacht.
Fazit
Dieser Lösungsansatz verdeutlicht, welches Optimierungspotential in den AI/ML for Fraud Prevention gestützten Lösungen steckt. Welche Schwierigkeiten hier vorliegen und welche Lösungen heute schon dafür existieren.

Kategorie: |
|
Schlagwörter: |
Banken und Finanzdienstleister Künstliche Intelligenz (KI) |
