



5. September 2019 von Dr. Stephan Pohl
Graphenorientierte Systeme
Die Finanzbranche befindet sich in einem tiefgreifenden Umbruch. Die Ansprüche von Kundinnen und Kunden steigen von Jahr zu Jahr, die gesetzlichen Rahmenbedingungen werden immer komplexer und die Bedrohungen durch Cyberkriminalität nehmen in exponentiellem Maße zu. In diesem Umfeld stoßen IT-Systeme, die auf relationalen Datenbanken basieren, immer mehr an ihre Grenzen. Zur Lösung dieses Problems setzen Banken-CIO‘s im Rahmen ihrer Big-Data-Strategien verstärkt auf graphenorientierte Datenbanken. Worum es sich dabei handelt, möchte ich euch im Folgenden näher erklären. Übrigens: Den größten Marktanteil hat die Datenbank Neo4j. Dieses Produkt ist für die Echtzeitverarbeitung großer Datenmengen ausgelegt und kann unter Amazon AWS Marketplace und in der Microsoft Azure Cloud betrieben werden. Zu den wichtigsten Kunden zählen unter anderem UBS, Lufthansa, AirBNB oder eBay.
Graphenorientierte Datenbanken – Was ist das und was sind die Vorteile?
Graphenorientierte Datenbanken speichern Daten in einer Netzwerkstruktur, die dem menschlichen Gehirn nachempfunden ist. Die Daten sind als Knoten mit frei definierbaren Eigenschaften – das heißt, den Nutzdaten – modelliert. Diese Nutzdaten sind ebenfalls über frei definierbare Beziehungen miteinander verbunden. Die Beziehungen können nach Bedarf gerichtet oder bidirektional definiert werden.
Die Vorteile für den Einsatz von Graphendatenbanken liegen auf der Hand:
Wissensgewinn: Graphendatenbanken ermöglichen tiefergehende Einblicke in die Zusammenhänge von Informationen, die miteinander verknüpft sind – etwa zu Kunden, Finanzprodukten oder Managementorganisationen. Diese „Schätze“ sind sicherlich auch in den Legacy-Systemen der Banken zu finden. Jedoch lagern sie häufig in den Untiefen des relationalen Modells, so dass sie nur mithilfe komplexer JOIN-Abfragen gehoben werden können. Im ungünstigsten Fall bleiben sie unentdeckt. Graphenorientierte Datenbanken hingegen sind genau auf das Sichtbarmachen komplexer Zusammenhänge ausgelegt. Sie ermöglichen auf intuitive Weise die Modellierung von Organisations- und Netzwerkstrukturen, die wiederum gezielt auf Kommunikationsengpässe, Schwachstellen, Kundenverhalten und sonstige Aspekte untersucht werden können. Das hieraus gewonnene Wissen mündet in konkreten Managemententscheidungen und schafft somit aus unternehmerischer Sicht einen Mehrwert.
Erweiterbarkeit: Graphenorientierte Datenbanken bilden konkrete Konzepte fachlicher Domänen und deren Beziehungen untereinander ab – zum Beispiel von Kunde A und Portfolio Z. Sie unterliegen dabei aber keinem statischen Schema. Entitäten können beliebig hinzufügt und in Beziehung zu bereits vorhandenen Konzepten gesetzt werden. Daher ist diese Art der Datenhaltung besonders geeignet für die Abbildung komplexer und sich häufig ändernder Sachverhalte. Aufwändige Migrationen mit langen Down Times, wie sie bei relationalen Systemen immer wieder anfallen, gehören auf diese Weise der Vergangenheit an.
Leistung: Abfragen auf relationalen Datenbanken über mehrere Tabellen hinweg werden mit zunehmender Größe langsamer. Ab einer bestimmten Größe ist diese Art der Informationsbeschaffung also nicht mehr ausreichend performant. Bei Graphendatenbanken besteht dieses Problem nicht, denn die Abfragen folgen dem Weg der bereits vorhandenen Beziehungen, anstatt sie zu berechnen. Hier wird nicht die Gesamtdatenmenge durchsucht, sondern die Suchanfragen navigieren entlang der Beziehungen. Das macht die Abfragen konstant, schnell und unabhängig von der Größe der Datenbank.
Die Einsatzgebiete für Graphendatenbanken
Ihr fragt euch, in welchen Bereichen Graphendatenbanken bereits heute erfolgreich zum Einsatz kommen? Ich verrate es euch:
Risikomanagement
Die Finanzkrise von 2008 hat gezeigt, dass die von Vermögensverwaltungen und Investmentfonds aufgelegten Portfolios eine kaum beherrschbare Komplexität aufweisen. Sie gliedern sich in zahllose Assets und Unter-Assets, die miteinander aufs Engste verbunden sind. Darüber hinaus werden Portfolios häufig aufgeschnürt und mit anderen Portfoliobündeln verschmolzen. Die Risiken, die in einem solchen Geflecht schlummern, sind nur mit großer Mühe oder zu spät auffindbar. Genau das hat in der Vergangenheit zu Verwerfungen am Finanzmarkt geführt. Um einen Asset Graph aufzubauen, setzen Finanzinstitute verstärkt Graphendatenbanken ein. Mithilfe dieser Struktur gewinnen die Entscheider ein vertieftes Verständnis über die Risiken, die bei den angebotenen Finanzinstrumenten entstehen. Der Asset Graph dient gleichfalls als Instrument für eine Preiskalkulation, welche die Chancen und Risiken des Portfolios objektiv widerspiegelt.
Regulatorik
Wie ihr sicherlich wisst, sind Finanzinstitute per Gesetz zur Offenlegung dedizierter Prozesse und Datenflüsse verpflichtet. Sie müssen gegenüber den Aufsichtsbehörden jederzeit Auskunft darüber geben können, welche Art von Daten inner- und außerhalb des Unternehmens ausgetauscht werden. Je nach Unternehmensgröße können hierbei hunderte von Backendsystemen, API-Schnittstellen und Replikationsservern beteiligt sein. Im Hinblick auf eine gesteigerte Übersichtlichkeit und Auskunftsfähigkeit gehen Banken schrittweise dazu über, die Datenflüsse und die beteiligten Systeme in Form eines Graphen zu verwalten.
Kundenbindung und -zufriedenheit
Im Sinne einer größeren Kundenzufriedenheit benötigen Banken eine 360-Grad-Kundensicht. Das ist jedoch etwas, über das die meisten Finanzinstitute nicht verfügen. Die relevanten Informationen über das Kundenverhalten sind in den Datensilos der einzelnen Geschäftsbereiche vergraben. Dies gilt umso mehr für die Interaktionen und Kommunikationswege des Kunden in dessen geschäftlichem Umfeld. Dieses Wissen um die Zusammenhänge ist anerkanntermaßen das eigentliche Kapital, mit dem sich Geschäftschancen generieren lassen. Der Aufbau eines graphenbasierten CRM-Systems geschieht in Koexistenz mit bereits bestehenden und herkömmlichen Stammdatensystemen. Hinzukommende Teildomänen werden schrittweise als Graphstruktur migriert und sukzessive mit den noch fehlenden „Zusammenhängen“ angereichert.
Ein ausführliches Beispiel: Betrugsprävention
Banken verlieren jährlich Milliarden Euro durch organisierte Kriminalität. Die Vorgehensweise ist häufig dieselbe: Eine oder mehrere Personengruppen schließen sich zu einem Ring zusammen. Die Mitglieder des Rings teilen miteinander Legitimierungsdaten zur Authentifizierung. Das heißt, sie haben dieselben Wohnorte und Telefonnummern, die sie zu immer neuen und falschen Identitäten kombinieren. Mit diesen künstlich geschaffenen Profilen werden bei den Kreditinstituten Konten eröffnet, über die wiederum nicht abgesicherte Kredite und Kreditkarten laufen. In einer ersten Phase weisen die Konten keine Auffälligkeiten auf, Abbuchungen und Gutschriften halten die Waage. Dieses Verhalten belohnen die Banken mit der Erhöhung der Überziehungsgrenzen. In Phase zwei platzt dann die Bombe: In einer konzertierten Aktion werden zeitgleich alle Kreditlinien und Kontolimits ausgeschöpft. Die unter den falschen Identitäten registrierten Personen sind aber nicht mehr auffindbar. In der dritten Phase sind die Banken dazu gezwungen, den so entstandenen Schaden als Verlust abschreiben.
Mithilfe von graphenorientierten Datenbanken ist es für Finanzfirmen heutzutage einfach, derartige Betrugsringe aufzuspüren und entsprechende Gegenmaßnahmen einzuleiten. In unserem Beispiel, das in etwas abgewandelter Form in den Neo4j–Tutorials zu finden ist, bilden wir drei Bankkunden ab - einschließlich Adressen, Telefonnummern, Bankkonten und Krediten. Neo4j visualisiert den Sachverhalt sehr anschaulich:
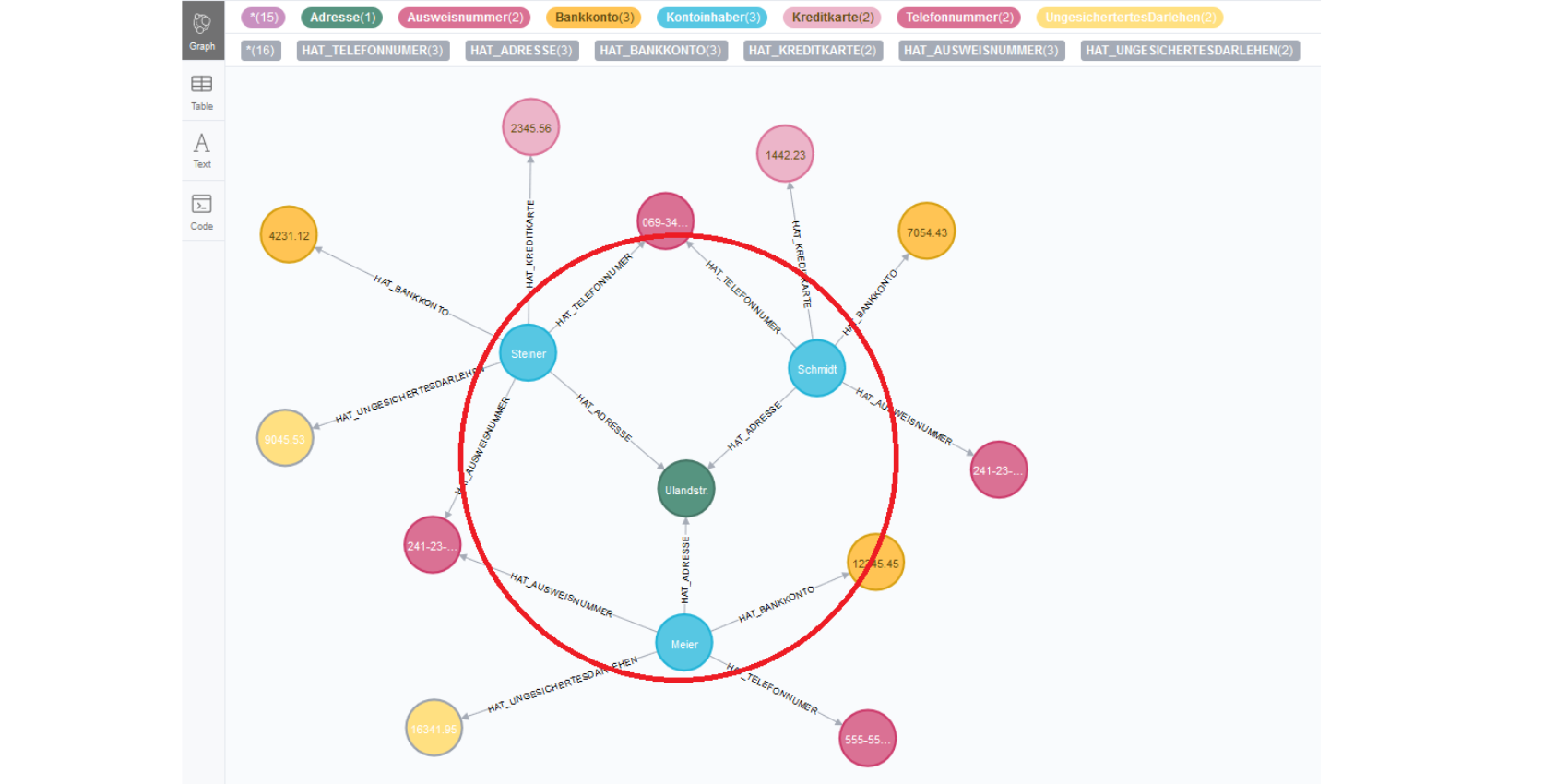
Über eine einfache Abfrage erhalten wir eine Aufstellung derjenigen Kontoinhaber, die mehr als eine legitimationsrelevante Information teilen:
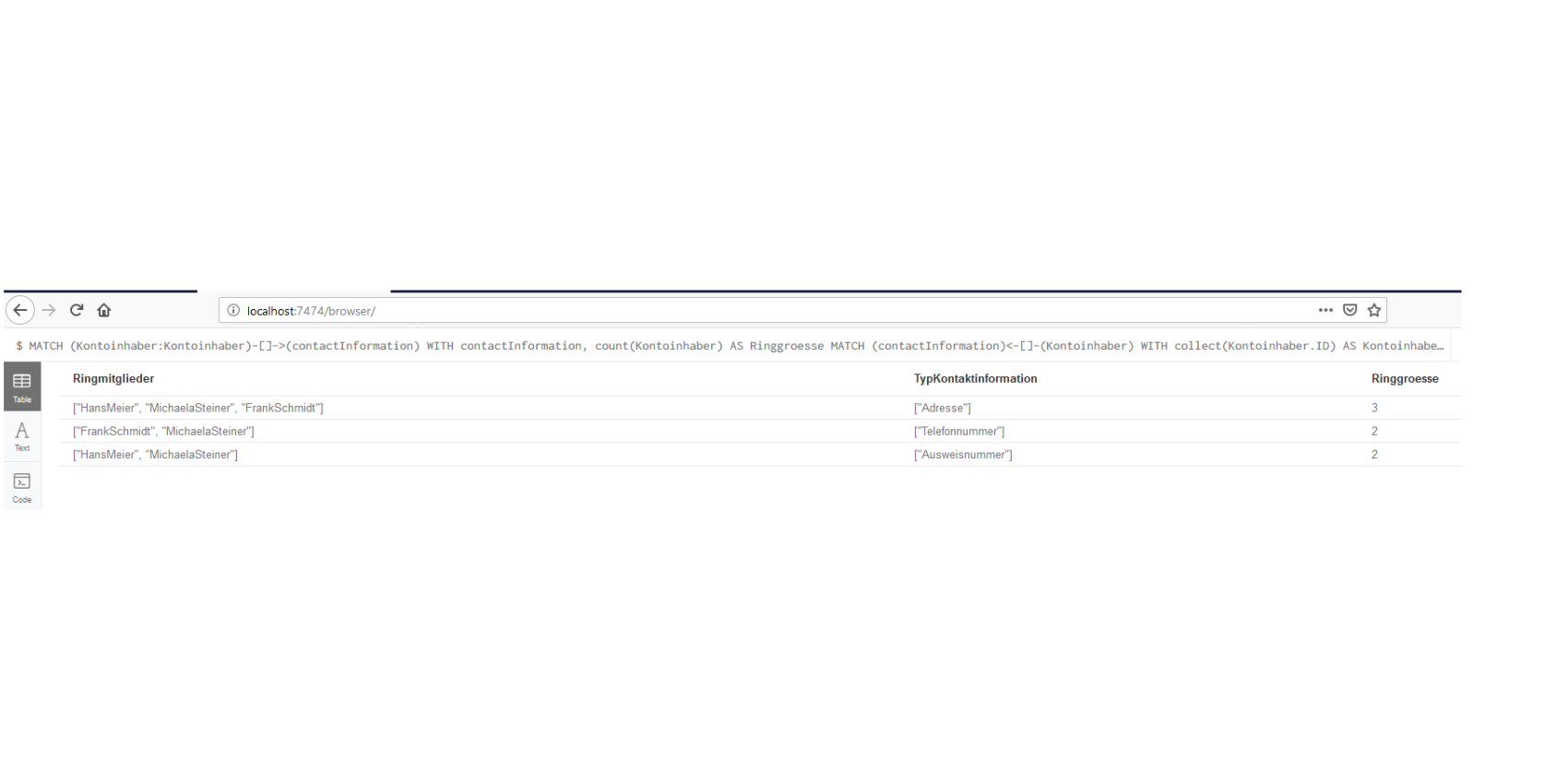
Die Ergebnistabelle besagt, dass drei Bankkunden (z.B. Hans Meier, Michaela Steiner und Frank Schmidt) dieselbe Adresse haben. Zwei Kunden (Michaela Steiner und Frank Schmidt) haben dieselbe Telefonnummer und zwei Kunden (Hans Meier und Michaela Steiner) dieselbe Ausweisnummer. Diese Auffälligkeiten deuten auf gemeinschaftliche und illegale Aktivitäten hin, die intensiv geprüft und eventuell den Aufsichtsbehörden und Strafverfolgern gemeldet werden müssen.
Eine weitere Abfrage liefert eine Statistik über den potenziellen finanziellen Schaden, der durch die aufgedeckte Ringstruktur entsteht. Die Grundlage der Berechnung bilden die Höhen der auszuschöpfenden Kreditlinien, Konten und Kreditkarten:
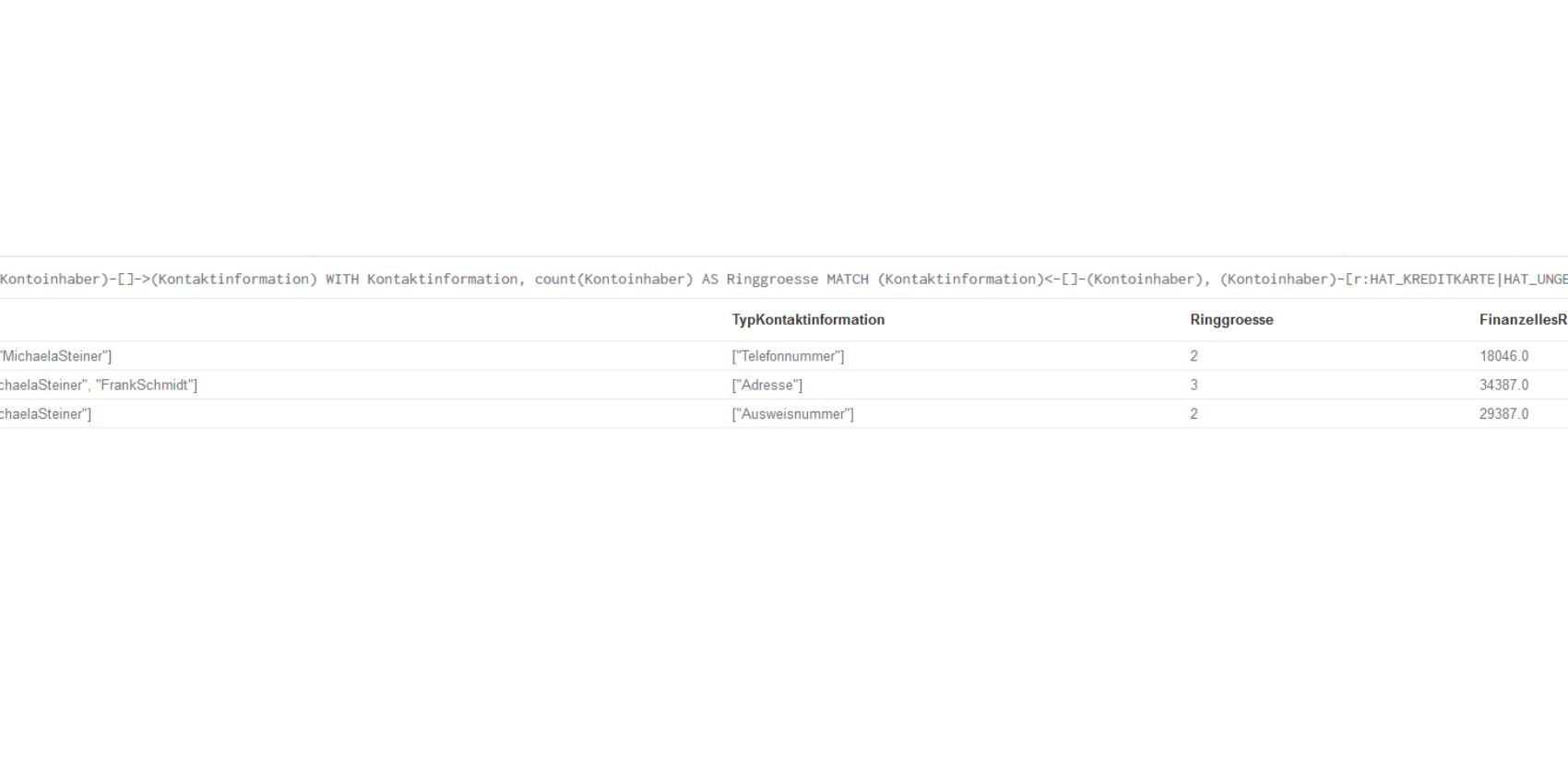
Die Statistikabfrage in der neo4j-Abfragesprache CypherQL sieht wie eine gewöhnliche SQL-Anweisung aus. Die Ausdrucksweise ist intuitiv und orientiert sich an der natürlichen Sprache:
MATCH (Kontoinhaber:Kontoinhaber)-[]->(Kontaktinformation)
WITH Kontaktinformation,
count(Kontoinhaber) AS Ringgroesse
MATCH (Kontaktinformation)<-[]-(Kontoinhaber),
(Kontoinhaber)-[r:HAT_KREDITKARTE|HAT_UNGESICHERTESDARLEHEN]->(ungesichertesKonto)
WITH collect(DISTINCT Kontoinhaber.ID) AS Kontoinhaber,
Kontaktinformation, Ringgroesse,
SUM(CASE type(r)
WHEN 'HAT_KREDITKARTE' THEN ungesichertesKonto.Limit
WHEN 'HAT_UNGESICHERTESDARLEHEN' THEN ungesichertesKonto.Kontostand
ELSE 0
END) as FinanzellesRisiko
WHERE Ringgroesse > 1
RETURN Kontoinhaber AS Ringmitglieder,
labels(Kontaktinformation) AS TypKontaktinformation,
Ringgroesse,
round(FinanzellesRisiko) as FinanzellesRisiko
Fazit
Wie ihr gesehen habt, gibt es zahlreiche Vorteile, die für den Einsatz von graphenorientierten Datenbanken sprechen und Finanzinstitute bei ihren Herausforderungen unterstützen. Sie dienen dazu, das Wissen um die Verbindungen zwischen den Daten aufzudecken und für das Tagesgeschäft nutzbar zu machen. Angesichts der sich gerade vollziehenden Umbrüche wäre es ein Fehler, an heterogenen Silolandschaften festzuhalten. Diese Silos gilt es aufzubrechen und zu vernetzen. Analysen von Marktforschungsunternehmen - beispielsweise Forrester Research - gehen folgerichtig davon aus, dass der Marktanteil von graphenorientierten Datenbanken mittelfristig signifikant steigen wird. Der Übergang zu neuen, wissensbasierten Systemlandschaften wird jedoch nicht im Hauruckverfahren zu erreichen sein. Altsysteme und eine „moderne“ IT werden noch für längere Zeit Seite an Seite fortbestehen und einander ergänzen.
Ihr möchtet mehr über spannende Themen aus dem Banking-Bereich erfahren? Dann werft doch auch einen Blick in unsere bisher erschienen Blog-Beiträge.

Kategorie: |
|
Schlagwörter: |
Kundenbindung Banken und Finanzdienstleister Regulatorik Kundenzufriedenheit |